
谷歌外链购买:什么是 Robots.txt 文件?
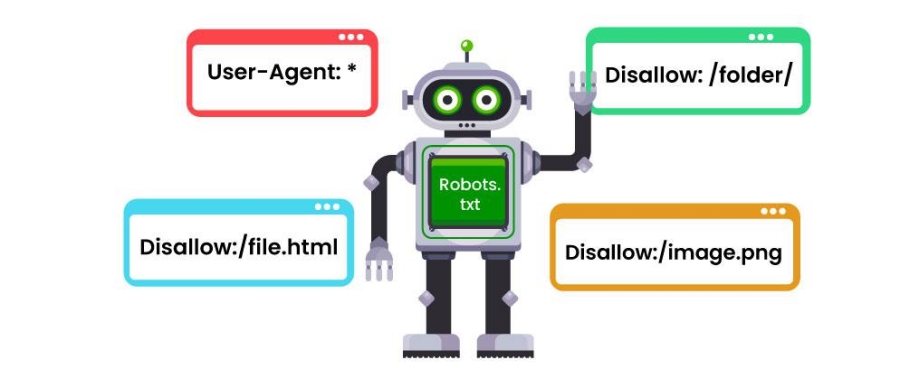
robots.txt 文件是一组指令,用于告诉搜索引擎要抓取哪些页面以及要避免抓取哪些页面,指导抓取工具访问,但不一定将页面排除在 Google 索引之外。robots.txt 文件可能看起来很复杂。但是,语法(计算机语言)很简单。在解释 robots.txt 的详细信息之前,我们将阐明 robots.txt 与其他听起来相似的术语有何不同。
robots.txt 与 Meta Robots 与 X-Robots的区别是什么?
robots.txt 文件、meta robots 标签和 x-robots 标签指导搜索引擎处理网站内容,但它们的控制级别、位置和控制内容有所不同。请考虑以下具体情况:
Robots.txt:此文件位于网站的根目录中,为搜索引擎爬虫提供网站范围内的说明,说明它们应该和不应该爬取网站的哪些区域
Meta robots 标签:这些标签是各个网页 <head> 部分中的代码片段,为搜索引擎提供页面特定的说明,说明是否索引(包含在搜索结果中)和跟踪(爬取每个页面上的链接)
X-robot 标签:这些代码片段主要用于非 HTML 文件,例如 PDF 和图像,并在文件的 HTTP 标头中实现
为什么 Robots.txt 对 SEO 很重要?
robots.txt 文件对 SEO 很重要,因为它有助于管理网络爬虫活动,以防止它们使您的网站超载并爬取不打算公开访问的页面。以下是使用 robots.txt 文件的几个原因:
1. 优化抓取预算
使用 robots.txt 阻止不必要的页面可让 Google 的网络抓取工具将更多抓取预算(Google 在特定时间范围内将抓取您网站上的页面数量)花在重要页面上。抓取预算可能因您网站的大小、健康状况和反向链接数量而异。如果您的网站页面数量超过其抓取预算,则重要页面可能无法编入索引。未编入索引的页面不会排名,这意味着您浪费了时间创建用户在搜索结果中永远不会看到的页面。
2. 阻止重复和非公开页面
并非所有页面都旨在包含在搜索引擎结果页面 (SERP) 中,robots.txt 文件可让您阻止抓取工具访问这些非公开页面。考虑暂存网站、内部搜索结果页面、重复页面或登录页面。某些内容管理系统会自动处理这些内部页面。
3. 隐藏资源
如果您希望将 PDF、视频和图像等资源保密或让 Google 专注于更重要的内容,Robots.txt 可让您将其排除在爬虫之外。
Robots.txt 文件如何工作?
robots.txt 文件会告诉搜索引擎机器人要爬取哪些 URL 以及(更重要的是)避免爬取哪些 URL。当搜索引擎机器人爬取网页时,它们会发现并跟踪链接。此过程会引导它们从一个网站到另一个网站,跨越多个页面。如果机器人找到 robots.txt 文件,它会在爬取任何页面之前读取该文件。语法很简单。您可以通过识别用户代理(搜索引擎机器人)并指定指令(规则)来分配规则。您可以使用星号 (*) 一次性将指令分配给所有用户代理。
如何查找 Robots.txt 文件?
您的 robots.txt 文件托管在您的服务器上,就像您网站上的其他文件一样。您可以通过在浏览器中输入网站主页 URL 并在末尾添加“/robots.txt”来查看任何网站的 robots.txt 文件。例如:
“https://semrush.com/robots.txt”。
如何创建 Robots.txt 文件?
使用 robots.txt 生成器工具快速创建 robots.txt 文件。按照以下步骤从头开始创建 robotx.txt 文件:
1. 创建文件并将其命名为 Robots.txt
在文本编辑器或 Web 浏览器中打开 .txt 文档。不要使用文字处理器,因为它们通常以专有格式保存文件,可以添加随机字符。将文档命名为“robots.txt”。您现在可以开始输入指令。
2. 将指令添加到 Robots.txt 文件
robots.txt 文件包含一组或多组指令,每组包含多行指令。每个组都以用户代理开头,并指定:
组适用于谁(用户代理)
代理应访问哪些目录(页面)或文件
代理不应访问哪些目录(页面)或文件
站点地图(可选),用于告诉搜索引擎您认为哪些页面和文件很重要
爬虫程序会忽略与上述指令不匹配的行。假设您不希望 Google 抓取您的“/clients/”目录,因为它仅供内部使用。文件中的第一个组将如下所示:
用户代理:Googlebot
Disallow:/clients/
用户代理:Googlebot
Disallow:/clients/
Disallow:/not-for-google
然后按两次 Enter 开始新的指令组。
现在假设您想阻止所有搜索引擎访问“/archive/”和“/support/”目录。阻止访问以下内容的阻止:
用户代理:Googlebot
禁止:/clients/
禁止:/not-for-google
用户代理:*
禁止:/archive/
禁止:/support/
完成后,添加您的站点地图:
用户代理:Googlebot
禁止:/clients/
禁止:/not-for-google
用户代理:*
禁止:/archive/
禁止:/support/
站点地图:https://www.yourwebsite.com/sitemap.xml
将文件另存为“robots.txt”
爬虫程序从上到下读取,并与第一个最具体的规则组匹配。因此,首先使用特定用户代理启动 robots.txt 文件,然后转到与所有爬虫程序匹配的更通用的通配符 (*)。
3. 上传 Robots.txt 文件
保存 robots.txt 文件后,将文件上传到您的网站,以便搜索引擎可以找到它。上传 robots.txt 文件的过程取决于您的托管环境。以下是一些解释如何将 robots.txt 文件上传到流行平台的链接:
WordPress 中的 Robots.txt
Wix 中的 Robots.txt
Joomla 中的 Robots.txt
Shopify 中的 Robots.txt
BigCommerce 中的 Robots.txt
上传后,确认该文件可访问且 Google 可以读取它。
4. 测试您的 Robots.txt 文件
首先,通过打开私人浏览器窗口并输入您的站点地图 URL,验证任何人都可以查看您的 robots.txt 文件。如果您看到 robots.txt 内容,请测试标记。Google 提供了两种测试选项:
Search Console 中的 robots.txt 报告
Google 的开源 robots.txt 库(高级)
定期检查您的 robots.txt 文件。即使是小错误也会影响您网站的可索引性。
5. 为不同的子域使用单独的 Robots.txt 文件
Robots.txt 文件仅控制其所在子域的抓取,这意味着您可能需要多个文件。如果您的网站是“domain.com”,而您的博客是“blog.domain.com”,请为域的根目录和博客的根目录创建一个 robots.txt 文件。
5 个要避免的 Robots.txt 错误
创建 robots.txt 文件时,请注意以下常见错误:
1. 未在根目录中包含 Robots.txt
您的 robots.txt 文件必须位于您网站的根目录中,以确保搜索引擎爬虫可以轻松找到它。例如,如果您网站的主页是“www.example.com”,请将文件放在“www.example.com/robots.txt”处。如果您将其放在子目录中,例如“www.example.com/contact/robots.txt”,搜索引擎可能找不到它,并可能认为您没有设置任何抓取指令。
2. 在 Robots.txt 中使用 Noindex 指令
不要在 robots.txt 中使用 noindex 指令——Google 不支持 robots.txt 文件中的 noindex 规则。相反,在各个页面上使用元 robots 标签(例如,<meta name="robots" content="noindex">)来控制索引。
3. 阻止 JavaScript 和 CSS
除非必要(例如,限制对敏感数据的访问),否则请避免通过 robots.txt 阻止对 JavaScript 和 CSS 文件的访问。阻止对 JavaScript 和 CSS 文件的抓取会使搜索引擎难以理解您网站的结构和内容,这可能会损害您的排名。
4. 不阻止访问您未完成的网站或页面
阻止搜索引擎抓取您网站的未完成版本,以防止在您准备好之前被发现(也可以为每个未完成的页面使用 meta robots noindex 标签)。搜索引擎抓取和索引正在开发的页面可能会导致糟糕的用户体验和潜在的重复内容问题。使用 robots.txt 将未完成的内容保密,直到您准备好发布。确保在线上不存在指向您正在开发的页面的链接。否则,人们和搜索引擎仍可以跟踪它们。
5. 使用绝对 URL
在您的 robots.txt 文件中使用相对 URL,使其更易于管理和维护。绝对 URL 是不必要的,如果您的域发生变化,可能会导致错误。绝对 URL 示例(不推荐):
用户代理:*
禁止:https://www.example.com/private-directory/
禁止:https://www.example.com/temp/
相对 URL 示例(推荐):
用户代理:*
禁止:/private-directory/
禁止:/temp/
允许:/important-directory/
保持 Robots.txt 文件无错误
现在您了解了 robots.txt 文件的工作原理,您应该确保您的 robots.txt 文件已优化。即使是小错误也会影响您的网站的抓取、索引和在搜索结果中的显示方式。
数聚梨软件为您提供最专业的独立站建站,谷歌seo优化服务,1-3个月内网站权重以及关键词进入谷歌前10页数量显著增加。
立即扫描二维码微信咨询中国国内最好的seo优化公司 数聚梨
相关搜索:
robots.txt generator
What robots txt is reddit
What robots txt is in seo
What robots txt is used for
robots.txt example
what is robot.txt in seo
robots.txt disallow all
robots.txt code
robots.txt 生成器
robots txt 是什么 reddit
robots txt 在 seo 中是什么
robots txt 有什么用
robots.txt 示例
robots.txt 在 seo 中是什么
robots.txt 禁止所有
robots.txt 代码
所有评论仅代表网友意见