Robots Meta Tag和X Robots Tag:您需要知道的一切

引导搜索引擎以所需方式对您的网站进行爬网和编制索引可能是一项艰巨的任务。尽管robots.txt管理着您的内容对抓取工具的可访问性,但它不会告诉他们是否应为内容编制索引。这就是Robots Meta Tag和X Robots Tag HTTP标头的用途。让我们从一开始就直言不讳。您无法使用robots.txt控制索引编制。这是一个普遍的误解。Google从未正式支持robots.txt中的noindex规则。并于2019年7月正式弃用。
什么是Robots Meta Tag?
Robots Meta Tag是一个HTML代码段,它告诉搜索引擎如何对特定页面进行爬网或编制索引。它放置在网页的<head>部分中,如下所示:
<meta name =“robots”content =“noindex”/>
为什么Robots Meta Tag对SEO很重要?
meta robots标记通常用于防止页面出现在搜索结果中,尽管它还有其他用途(稍后会详细介绍)。您可能希望阻止搜索引擎建立索引的各种类型的内容:
对用户几乎没有价值的薄页
暂存环境中的页面
管理员和感谢页面
内部搜索结果
PPC登陆页面
有关即将进行的促销,竞赛或产品发布的页面
重复的内容(使用规范标签建议最佳的索引版本)
通常,您的网站越大,您就越会处理可爬网性和索引编制工作。您还希望Google和其他搜索引擎尽可能高效地对页面进行爬网和索引。将页面级指令与robots.txt和站点地图正确结合对于SEO至关重要。
Robots Meta Tag的值和属性是什么?
Robots Meta Tag包含两个属性:名称和内容。您必须为每个这些属性指定值。让我们探讨一下这些是什么。
名称属性和用户代理值
name属性指定哪些爬网程序应遵循这些说明。此值也称为用户代理(UA),因为需要使用其UA标识搜寻器以请求页面。 UA反映了您使用的浏览器,但是Google的用户代理是例如Googlebot或Googlebot映像。
UA值“机器人”适用于所有爬网程序。您还可以根据需要在<head>部分中添加任意数量的Robots Meta Tag。例如,如果要防止图像显示在Google或Bing图像搜索中,请添加以下元标记:
<meta name =“googlebot-image”content =“noindex”/>
<meta name =“MSNBot-Media”content =“noindex”/>
边注。名称和内容属性都不区分大小写。“Googlebot-Image”,“msnbot-media”和“Noindex”属性也适用于以上示例。
内容属性和爬网/索引指令
content属性提供有关如何对页面上的信息进行爬网和编制索引的说明。如果没有可用的Robots Meta Tag,抓取工具会将其解释为索引并遵循。这样,他们就可以在搜索结果中显示该页面并抓取该页面上的所有链接(除非使用rel =“nofollow”标记另行声明)。以下是Google的content属性支持的值:
All
默认值为“index,follow”,无需使用此伪指令。
<meta name =“robots”content =“all”/>
Noindex
指示搜索引擎不要为页面编制索引。这样可以防止它显示在搜索结果中。
<meta name =“robots”content =“noindex”/>
Nofollow
阻止漫游器抓取页面上的所有链接。请注意,这些URL仍可索引,尤其是当它们具有指向它们的反向链接时。
<meta name =“robots”content =“nofollow”/>
None
noindex,nofollow的组合。避免使用此功能,因为其他搜索引擎(例如Bing)不支持此功能。
<meta name =“robots”content =“none”/>
Noarchive
阻止Google在SERP中显示页面的缓存副本。
<meta name =“robots”content =“noarchive”/>
Notranslate
阻止Google在SERP中提供页面翻译。
<meta name =“robots”content =“notranslate”/>
noimageindex
阻止Google将网页上嵌入的图像编入索引。
<meta name =“robots”content =“noimageindex”/>
unavailable_after:
告诉Google在指定的日期/时间之后不在搜索结果中显示页面。基本上是带有计时器的noindex指令。必须使用RFC 850格式指定日期/时间。
<meta name =“robots”content =“unavailable_after:Sunday,01-Sep-19 12:34:56 GMT”/>
Nosnippet
选择退出SERP中的所有文本和视频片段。同时也可以用作存档。
<meta name =“robots”content =“nosnippet”/>
max-snippet:
指定Google可以在其文本片段中显示的最大字符数。使用0将退出文本摘录,-1声明文本预览没有限制。以下标记将限制限制为160个字符(类似于标准元描述长度):
<meta name =“robots”content =“max-snippet:160”/>
max-image-preview:
告诉Google图片片段是否可以使用以及图片可以使用多大。该指令具有三个可能的值:
没有没有图像片段将被显示
标准-可能会显示默认图像预览
大—可能会显示最大的图像预览
<meta name =“robots”content =“max-image-preview:large”/>
max-video-preview:
设置视频片段的最大秒数。与文本代码段一样,0将完全退出,-1没有限制。以下标记将使Google最多显示15秒:
<meta name =“robots”content =“max-video-preview:15”/>
如何使用这些指令?
大多数SEO不需要超越noindex和nofollow指令,但是很高兴知道还有其他选择。请记住,上面列出的所有指令均受Google支持。您可以一次使用多个指令并将其组合。但是,如果它们发生冲突(例如“noindex,index”)或一个是另一个子集(例如“noindex,noarchive”),则Google将使用限制性最强的一个。在这些情况下,它将只是“noindex”。
如何设置Robots Meta Tag
现在您已经了解了所有这些指令的功能和外观,现在是时候在您的网站上进行实际的实现了。Robots Meta Tags属于页面的<head>部分。如果您使用Notepad ++或Brackets等HTML编辑器来编辑代码,则非常简单。但是,如果您将CMS与SEO插件配合使用,该怎么办?让我们集中讨论最流行的选项。
使用Yoast SEO在WordPress中实现Robots Meta Tag
转到每个帖子或页面的编辑块下方的“高级”部分。根据您的需要设置Robots Meta Tag。以下设置将实现“noindex,nofollow”指令。“Meta robots advanced”行为您提供了实现noindex和nofollow之外的指令的选项,例如noimageindex。您还可以选择在整个站点上应用这些指令。转到Yoast菜单中的“搜索外观”。在那里,您可以在所有帖子,页面或仅在特定分类法或档案上设置meta robots tag。
什么是X Robots Tag?
robots meta tag非常适合在此处和此处的HTML页面上实现noindex指令。但是,如果您想防止搜索引擎将图像或PDF等文件编入索引,该怎么办?这是X Robots Tag发挥作用的时候。X Robots Tag是从Web服务器发送的HTTP标头。与meta robots标记不同,它不会放置在页面的HTML中。看起来像这样:
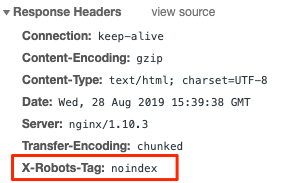
检查HTTP标头要复杂一些。您可以使用开发人员工具的旧方法进行操作,也可以使用“Live HTTP Headers”之类的浏览器扩展程序。实时HTTP标头扩展可监视浏览器发送的所有HTTP(S)流量(请求标头)和接收的所有HTTP(S)流量(响应标头)。它是实时捕获的,因此请确保插件已激活。然后转到您要检查的页面或文件,并检查插件的日志。
如何设置X Robots Tag?
配置取决于您使用的网络服务器的类型以及要保留在索引范围之外的页面或文件。代码行如下所示:
Header set X Robots Tag “noindex”
此示例考虑了最广泛使用的服务器类型-Apache。添加HTTP标头的最实用方法是修改主配置文件(通常为httpd.conf)或.htaccess文件。听起来很熟悉?这也是重定向发生的地方。您对X Robots Tag使用与meta robots tag相同的值和指令。也就是说,实施这些更改应该留给有经验的人。备份是您的朋友,因为即使是很小的语法错误也可能会破坏整个网站。
何时使用Robots Meta Tag和X Robots Tag?
尽管添加HTML代码段看起来是最简单,最直接的选项,但在某些情况下它还是不够用的。
非HTML文件
您不能将HTML代码段放入非HTML文件(例如PDF或图像)中。X Robots Tag是唯一的方法。以下代码段(在Apache服务器上)将在站点上的所有PDF文件上配置noindex HTTP标头。
<Files ~ "\.pdf$">
Header set X Robots Tag "noindex"
</Files>
如果您不需要索引整个(子)域,子目录,具有某些参数的页面或需要批量编辑的其他任何内容,请使用X Robots Tags。更容易。可以使用正则表达式将HTTP标头修改与URL和文件名进行匹配。使用搜索和替换功能在HTML中进行复杂的批量编辑通常会需要更多的时间和计算能力。
来自Google以外的搜索引擎的流量
Google同时支持meta robots tag和X Robots Tags,但并非所有搜索引擎都如此。例如,捷克搜索引擎Seznam仅支持Robots Meta Tag。如果您想控制此搜索引擎对网页进行爬网和编制索引的方式,则无法使用X Robots Tags。您需要使用HTML代码段。
写在最后
正确地理解和管理网站的爬网和索引是SEO的基础。 技术性SEO可能非常复杂,但是Robots Meta Tag就不用担心了。希望您现在准备将最佳实践大规模应用到长期解决方案中。
数聚梨软件为您提供最专业的谷歌seo优化服务,1-3个月内网站权重以及关键词进入谷歌前10页数量显著增加
立即扫描二维码微信咨询